������: boris963 (txj), ����: XML
�� ��:
��ת�ء�XSLT�������������������� ����վ: BBS ˮľ�廪վ (Tue Apr 20 10:53:40 2004)
�ڱ����У�Benoit Marchal ������ XSLT ��������Ĺ���ԭ����Ϊ��˵�����Ĺ۵㣬����
д��ר�ŵ���ʽ���Ѵ����е�ijЩ�����Գ��������ر�ǿ���� XSLT ����ĵݹ��ԡ��ܺ�
������ XSLT �����������������ΪЧ�ʸ��ߵ� XSLT ����Ա��
��ѧ��һ�������������ŵ�ѧϰ���顣���ڹ�˾����ѵ�γ̺��йػ�����Ϊ������Ա���� X
ML �� XSLT����������Ϊ����ѧԱ����һ�����ӵ�����������Ŭ��ʹ���Լ������˶������
���⡣�Ҳ��������ڽ��ҵ�ѧԱ��Ҳ���ڽ����Լ���
���⣬ѧԱҲ������Լ������Ĺ۵㣬������ʹ������˼�������ijЩ���沢�ó��µĽ���
�����ľ�Դ��������һ�ξ���������ʶ���Ӵ��� JSP��PHP��ASP �� ColdFusion ��ѧԱ��
���� XSLT ���в���ȷ�����룬�����������ɴ���ı��롣��Ѱ����γ�����һ����ʱ��
�ҿ�ʼ˼�� XSLT ���������� Xalan��Saxon �� MSXML����������ι����ġ������µĿ�
����ĽǶȸ����Ұ��������Ŷ���Ҳ���������档
������������
�������������� Web ��������֮���кܶ�����֮������ JSP �� PHP �Լ� XSLT�������Ե�
�����Ƕ�����������Ա�� HTML ��ǩ�л�ϱ��룺JSP ʹ�� Java ��д���룬PHP ʹ���ر�
�Ľű����ԣ������� XSLT �������� XSLT ���ƿռ�� XML ��ǩ��
���������������˱��ʵ����𡣶��� JSP���Լ� PHP��ASP �� ColdFusion����HTML ��ǩ��
��Ϊ�ı���������ʵ�ϣ��� JASP ҳ���� servlet �б���ʱ�����е� HTML ��ǩ����ת��
��д����С������ϣ���ǩ�����Ļ�Ͻ�����Ϊ�˷����д���롪������ζ��������Ҫ��
д������д��䡣
�� XSLT ȴ����������XSLT ��������ѱ�ǩ�������ϵȹ���XSLT �еġ�T������ת����T
ransformation����ת��ʲô�أ��� XML �ĵ�ת������һ�� XML �ĵ���HTML ����Ϊ�� XML
��һ�ֱ��壩�����߸�ȷ��˵������ת��������������ʲô�� �� �أ���һ�� W3C DOM
���� Java �������� org.w3c.dom ���������ܳ������ܵ�ԭ���ִ� XSLT ���������ڲ�
����ʹ�� DOM��һ���Ż�������Ч���������������ڰ� XSLT �����Ǵ�һ�� DOM ��ת��
����һ�� DOM �������ԡ�
�� JSP �� PHP ��ͬ��XSLT ���������ǰѱ�ǩäĿ��д��������෴��XSLT ��������
�Ĺ������£�
��Ϊ DOM �������ڲ������������Ż��� DOM�����ⲻӰ�����ǵ����ۣ����������ĵ���
������������������ȵı�����������ڱ�� 101 ����ѧ����������㷨û��ʲô��ͬ��
�����ĵ��Ĺ����У�Ϊ��ǰ�ڵ�����ʽ����ѡ��һ��ģ�塣
Ӧ�ø�ģ�壬ģ�������������������д��� 0 ����1 �������ڵ㡣
�������ʱ��������������ģ���еĹ�������һ�����������������
���� HTML ���� XML ���������
ע�⣬Ҳ����ѡ��������ȱ���֮��������㷨����������Ҫǿ������ XSLT �����������
���������������������ִ�����ʽ���������ֽ����
����������Ըı�������� xsl:output ����ֵ��������������� XML ���� HTML
�д������Web �������Բ�������������Ϊ���ǰ� HTML ��ǩ�������ı���äĿ�ظ���
�������
��Ȼż�����ܳ�������������������֤����ǽṹ���õ� XML �ĵ���
������Ա���밴�������������Լ������⡣
��һ�����ҽ�˵����仰�ĺ��塣
������ȵı���
��һ�ڽ��Ƚ�������ʽ������һ���ǵ��͵� XSLT ��ʽ�����ڶ����Ե�һ�������˸�д����
�㹫�������õ�������ȱ����㷨����Ȼ������������ֱ������������ڽ��ʹ�����
������ι����ġ�
������ʽ��
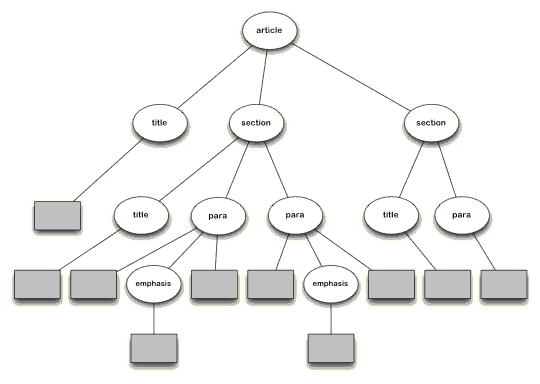
�嵥 1 ��һ��ʾ�� XML �ĵ���ͼ 1 ����Ӧ�� DOM �����嵥 2 ��һ������ʽ������
���嵥 1 ת���� HTML��
�嵥 1. XML �ĵ�
<?xml version="1.0"?>
<db:article xmlns:db="
http://ananas.org/2002/docbook/subset"> <db:title>XSLT, JSP and PHP</db:title>
<db:section>
<db:title>Is there a difference?</db:title>
<db:para>Yes there is! XSLT is a pure XML technology that
traces its roots to <db:emphasis>tree manipulation
algorithms</db:emphasis>. JSP and PHP offer an ingenious
solution to combine scripting languages with HTML/XML
tagging.</db:para>
<db:para>The difference may not be obvious when you're first
learning XSLT (after all, it offers tags and instructions),
but understanding the difference will make you a
<db:emphasis role="bold">stronger and better</db:emphasis>
developer.</db:para>
</db:section>
<db:section>
<db:title>How do I learn the difference?</db:title>
<db:para>Interestingly enough, you can code the XSLT algorithm
in XSLT... one cool way to experiment with the
difference.</db:para>
</db:section>
</db:article>
�嵥 2. ת���� HTML �ļ���ʽ��
<?xml version="1.0"?>
<xsl:stylesheet version="1.0"
xmlns:xsl="
http://www.w3.org/1999/XSL/Transform" xmlns:db="
http://ananas.org/2002/docbook/subset"> <xsl:output method="html"/>
<xsl:template match="db:article">
<html>
<head><title>
<xsl:value-of select="db:articleinfo/db:title"/>
</title></head>
<body>
<xsl:apply-templates/>
</body>
</html>
</xsl:template>
<xsl:template match="db:para">
<p><xsl:apply-templates/></p>
</xsl:template>
<xsl:template match="db:ulink">
<a href="{@url}"><xsl:apply-templates/></a>
</xsl:template>
<xsl:template match="db:article/db:title">
<h1><xsl:apply-templates/></h1>
</xsl:template>
<xsl:template match="db:title">
<h2><xsl:apply-templates/></h2>
</xsl:template>
<xsl:template match="db:emphasis[@role='bold']">
<b><xsl:apply-templates/></b>
</xsl:template>
<xsl:template match="db:emphasis">
<i><xsl:apply-templates/></i>
</xsl:template>
</xsl:stylesheet>
ͼ 1. ���������������� XML �ĵ�
��ע����ͼ���ڸ�����
�����㷨
��һ�ڵ�Ŀ���Ǹ�д �嵥 2�������������ʾ������ȱ����㷨��Ϊ������Ҫһ������ģ
�塣�������Ϥ����ģ�壬���Ǿ��൱�� XSLT �еķ������ã�����ģ���Ǵ��� name ����
��ģ�塣��ͨ�� xsl:param ָ����ܲ�����������������
<xsl:template name="print">
<xsl:param name="message"/>
<!-- template content goes here -->
</xsl:template>
xsl:call-template ָ�����ڵ�������ģ�壨������ xsl:apply-templates�������磺
<xsl:call-template name="print">
<xsl:with-param name="message"
select="'See if it prints this message.'"/>
</xsl:call-template>
�嵥 3 �Ƕ� �嵥 2 �ĸ�д����ʹ�����ı����㷨�����ԡ�Ϊ�˱��������������������
�������ʽ����һ������ģ�� main ʵ�������ı�����main ��һ���ݹ麯�������� curren
t ��������һ���ڵ㼯�������ýڵ㼯��ģ�����Ҫ������һ�� choose ָ�Ϊ�����Ľ�
��Ѱ�����ʵ��Ĺ����ڴ���һ���ڵ�ʱ����ģ��ݹ�ص����������Ա㴦���ýڵ�ĺ���
��
�嵥 3. ���������㷨����ʽ��
<?xml version="1.0"?>
<xsl:stylesheet version="1.0"
xmlns:xsl="
http://www.w3.org/1999/XSL/Transform" xmlns:db="
http://ananas.org/2002/docbook/subset"> <xsl:output method="html"/>
<xsl:template match="/">
<xsl:call-template name="main">
<xsl:with-param name="nodes" select="."/>
</xsl:call-template>
</xsl:template>
<xsl:template name="main">
<xsl:param name="nodes"/>
<xsl:for-each select="$nodes">
<xsl:choose>
<xsl:when test="self::db:article">
<html>
<head><title>
<xsl:value-of select="db:title"/>
</title></head>
<body>
<xsl:call-template name="main">
<xsl:with-param name="nodes" select="child::node()"/>
</xsl:call-template>
</body>
</html>
</xsl:when>
<xsl:when test="self::db:para">
<p>
<xsl:call-template name="main">
<xsl:with-param name="nodes" select="child::node()"/>
</xsl:call-template>
</p>
</xsl:when>
<xsl:when test="self::db:ulink">
<a href="{@url}">
<xsl:call-template name="main">
<xsl:with-param name="nodes" select="child::node()"/>
</xsl:call-template>
</a>
</xsl:when>
<xsl:when test="self::db:title[parent::db:article]">
<h1>
<xsl:call-template name="main">
<xsl:with-param name="nodes" select="child::node()"/>
</xsl:call-template>
</h1>
</xsl:when>
<xsl:when test="self::db:title">
<h2>
<xsl:call-template name="main">
<xsl:with-param name="nodes" select="child::node()"/>
</xsl:call-template>
</h2>
</xsl:when>
<xsl:when test="self::db:emphasis[@role='bold']">
<b>
<xsl:call-template name="main">
<xsl:with-param name="nodes" select="child::node()"/>
</xsl:call-template>
</b>
</xsl:when>
<xsl:when test="self::db:emphasis">
<i>
<xsl:call-template name="main">
<xsl:with-param name="nodes" select="child::node()"/>
</xsl:call-template>
</i>
</xsl:when>
<xsl:when test="self::text()">
<xsl:value-of select="."/>
</xsl:when>
<xsl:otherwise>
<xsl:call-template name="main">
<xsl:with-param name="nodes" select="child::node()"/>
</xsl:call-template>
</xsl:otherwise>
</xsl:choose>
</xsl:for-each>
</xsl:template>
</xsl:stylesheet>
����Ƚ��嵥 2 ���嵥 3���ͻᷢ�������ڽṹ����һ�µġ��� �嵥 2 �У���� choo
se ָ����ͨ��ģ����Ļ��ʵ�ֵġ�����Ҫ��ʽ��д�� choose ָ�����ȷʵ�Ǵ�������
�����ķ�ʽ���Ƚ��嵥 2 �е�ģ��� �嵥 3 �еIJ����������ͻᷢ�ִ���һһ��Ӧ�Ĺ�
ϵ��
��ʹ�嵥 3 �е�����������ԣ�Ҳͨ��Ĭ��ģ�����嵥 2 ��Ӧ����Ȼ������Ĭ��ģ�壬��
�� 2 �в���Ҫ��ȷ��д��������ģ�壬��������ȷʵ������ģ�壬һ�������ı����ݺ���
һ����catch-all��ģ�塣
�嵥 2 �У�xsl:apply-templates ָ������˵ݹ���á��ںܶ�棬������Ϊ xsl:appl
y-templates �Ƕ���ʽ�������ĵݹ���ã������ߴ��������Ƶ���ǰ�ڵ�ĺ��ӣ�������Ѱ
����һ�����õ�ģ�塣�嵥 3 �е�ѭ���Ͳ��Էdz����ԣ������嵥 2 �����ɴ�����������
��ɵġ����嵥 3 �У� ģ��ʹ����һ������IJ�����ʾ��ǰ�ڵ㣬�����嵥 2 �У��ò�
������ʽ�ġ�xsl:apply-templates �Զ��ı䵱ǰ�ڵ㡣
���ͬ����Ҫ��һ����ģ��������� �嵥 3��ģ��ʹ�ò�����ʾҪ�����Ľڵ㡣�� �嵥
2��ģ�岻��Ҫ��������Ϊ���������������ǰ�ڵ㡣��ǰ�ڵ�����ָ��ģ����Ӧ�õĽ�
�㡣��ǰ�ڵ������һ����ʽ������
������
��ʵ�ϣ�û���˻��д �嵥 3 ��������ʽ����������ӽ����ڽ�ѧ����ȷʵ����˵������
������Ļ������ι����ġ�ͨ���Ƚ��嵥 2 ���嵥 3�����Կ��������������˺ܶ����
���루����ѭ���ʹ��ݲ��������Ա�ʵ��������ȵ���������д��һ����ʽ��ʱҪ����Щ��
�������Ҳ�����ᷢ�����ı���������ķ�ʽ��
���磬������ XSLT ���ֳ�����������д���ִ��룺
<xsl:template match="db:emphasis">
<xsl:choose>
<xsl:when test="@role='bold'">
<b><xsl:apply-templates/></b>
</xsl:when>
<xsl:otherwise><i><xsl:apply-templates/></i></xsl:otherwise>
</xsl:choose>
</xsl:template>
�����Ը�д������������������ǵ���������Ĺ���ԭ������������ȫ�ȼ۵ģ�
<xsl:template match="db:emphasis[@role='bold']">
<b><xsl:apply-templates/></b>
</xsl:template>
<xsl:template match="db:emphasis">
<i><xsl:apply-templates/></i>
</xsl:template>
��ϣ���Ѿ�˵���� XSLT ����������ڲ�����ԭ�����ܺõ�������һ����ڸĽ�������ʽ��
����dz���Ҫ��
 ���������ͼƬ���£�
���������ͼƬ���£�

 [����] ����XML��̳ - רҵ��XML���������� ��
XML.ORG.CN������ - XML���� �� �� XSL/XSLT/XSL-FO/CSS �� �� [ת��]XSLT��������������������
[����] ����XML��̳ - רҵ��XML���������� ��
XML.ORG.CN������ - XML���� �� �� XSL/XSLT/XSL-FO/CSS �� �� [ת��]XSLT��������������������



 (���ı���)
(���ı���)






 ������
������









 [ת��]XSLT��������������������
[ת��]XSLT��������������������
