-- 发布时间:4/20/2004 1:43:00 PM
-- [转帖]XSLT处理程序是怎样工作的
发信人: boris963 (txj), 信区: XML
标 题: 【转载】XSLT处理程序是怎样工作的
发信站: BBS 水木清华站 (Tue Apr 20 10:53:40 2004)
在本文中,Benoit Marchal 考察了 XSLT 处理程序的工作原理。为了说明他的观点,他编
写了专门的样式表把处理中的某些方面凸显出来。他特别强调了 XSLT 编码的递归性。很好
地理解 XSLT 处理程序可以帮助您成为效率更高的 XSLT 程序员。
教学是一种令人难以置信的学习体验。我在公司的培训课程和有关会议上为开发人员讲授 X
ML 和 XSLT,经常发现为了向学员澄清一个复杂的问题所作的努力使我自己加深了对问题的
理解。我不仅仅是在教我的学员,也是在教我自己。
另外,学员也会带来自己独到的观点,常常迫使我重新思考问题的某些方面并得出新的结论
。本文就源于这样的一次经历。我认识到接触过 JSP、PHP、ASP 或 ColdFusion 的学员经
常对 XSLT 抱有不正确的设想,这种设想会造成错误的编码。在寻求如何澄清这一问题时,
我开始思考 XSLT 处理程序(如 Xalan、Saxon 或 MSXML)到底是如何工作的。这种新的看
问题的角度给了我帮助,相信对您也会有所助益。
相似性与区别
初看起来,各种 Web 开发语言之间有很多相似之处,如 JSP 或 PHP 以及 XSLT。最明显的
,它们都允许开发人员在 HTML 标签中混合编码:JSP 使用 Java 编写代码,PHP 使用特别
的脚本语言,而对于 XSLT 代码则是 XSLT 名称空间的 XML 标签。
这种相似性隐藏了本质的区别。对于 JSP(以及 PHP、ASP 和 ColdFusion),HTML 标签被
作为文本处理。事实上,当 JASP 页面在 servlet 中编译时,所有的 HTML 标签都被转移
到写语句中。基本上,标签与代码的混合仅仅是为了方便编写代码――这意味着您不需要编
写大量的写语句。
而 XSLT 却不是这样。XSLT 处理程序把标签看成是上等公民。XSLT 中的“T”代表转换(T
ransformation)。转换什么呢?把 XML 文档转换成另一个 XML 文档(HTML 被认为是 XML
的一种变体),或者更准确地说,把树转换成其他的树。什么是 树 呢?想一想 W3C DOM
(在 Java 技术中是 org.w3c.dom 包)。尽管出于性能的原因,现代 XSLT 处理程序内部
并不使用 DOM(一个优化库会更有效),但这样有助于把 XSLT 看作是从一棵 DOM 树转换
成另一棵 DOM 树的语言。
和 JSP 或 PHP 不同,XSLT 处理程序并不是把标签盲目地写入输出。相反,XSLT 处理程序
的工作如下:
作为 DOM 树(在内部,处理程序优化了 DOM,但这不影响我们的讨论)加载输入文档。
对输入树进行深度优先的遍历,这和您在编程 101 中所学的深度优先算法没有什么不同。
遍历文档的过程中,为当前节点在样式表中选择一个模板。
应用该模板,模板描述了如何在输出树中创建 0 个、1 个或多个节点。
遍历完成时,按照输入树和模板中的规则生成一棵新树(输出树)。
根据 HTML 或者 XML 语法写入输出树。
注意,也可以选择深度优先遍历之外的其他算法。但这里我要强调的是 XSLT 处理程序把输
入和输出都看作是树。这种处理方式带来了三种结果:
处理程序可以改变语法。根据 xsl:output 语句的值,处理程序可以按照 XML 或者 HTML
语法写入结果。Web 开发语言不能这样做,因为它们把 HTML 标签看作是文本,盲目地复制
到输出中。
虽然偶尔可能出错,但处理程序尽量保证输出是结构良好的 XML 文档。
开发人员必须按照树操作表达自己的问题。
下一节中我将说明这句话的含义。
深度优先的遍历
这一节将比较两个样式表。第一个是典型的 XSLT 样式表,第二个对第一个进行了改写,以
便公开所采用的深度优先遍历算法。虽然您不会采用这种编码风格,但它有助于解释处理程
序是如何工作的。
常规样式表
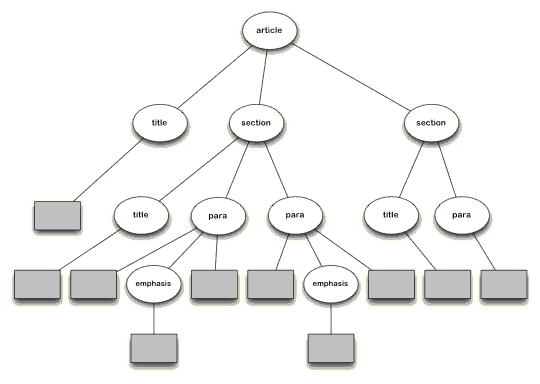
清单 1 是一个示例 XML 文档,图 1 是相应的 DOM 树。清单 2 是一个简单的样式表,它
把清单 1 转换成 HTML。
清单 1. XML 文档
<?xml version="1.0"?>
<db:article xmlns:db="http://ananas.org/2002/docbook/subset">
<db:title>XSLT, JSP and PHP</db:title>
<db:section>
<db:title>Is there a difference?</db:title>
<db:para>Yes there is! XSLT is a pure XML technology that
traces its roots to <db:emphasis>tree manipulation
algorithms</db:emphasis>. JSP and PHP offer an ingenious
solution to combine scripting languages with HTML/XML
tagging.</db:para>
<db:para>The difference may not be obvious when you're first
learning XSLT (after all, it offers tags and instructions),
but understanding the difference will make you a
<db:emphasis role="bold">stronger and better</db:emphasis>
developer.</db:para>
</db:section>
<db:section>
<db:title>How do I learn the difference?</db:title>
<db:para>Interestingly enough, you can code the XSLT algorithm
in XSLT... one cool way to experiment with the
difference.</db:para>
</db:section>
</db:article>
清单 2. 转换成 HTML 的简单样式表
<?xml version="1.0"?>
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:db="http://ananas.org/2002/docbook/subset">
<xsl:output method="html"/>
<xsl:template match="db:article">
<html>
<head><title>
<xsl:value-of select="db:articleinfo/db:title"/>
</title></head>
<body>
<xsl:apply-templates/>
</body>
</html>
</xsl:template>
<xsl:template match="db:para">
<p><xsl:apply-templates/></p>
</xsl:template>
<xsl:template match="db:ulink">
<a href="{@url}"><xsl:apply-templates/></a>
</xsl:template>
<xsl:template match="db:article/db:title">
<h1><xsl:apply-templates/></h1>
</xsl:template>
<xsl:template match="db:title">
<h2><xsl:apply-templates/></h2>
</xsl:template>
<xsl:template match="db:emphasis[@role='bold']">
<b><xsl:apply-templates/></b>
</xsl:template>
<xsl:template match="db:emphasis">
<i><xsl:apply-templates/></i>
</xsl:template>
</xsl:stylesheet>
图 1. 处理程序所看到的 XML 文档
『注:此图放于附件』
遍历算法
这一节的目标是改写 清单 2,更加清楚地显示深度优先遍历算法。为此您需要一个命名模
板。如果不熟悉命名模板,它们就相当于 XSLT 中的方法调用:命名模板是带有 name 属性
的模板。它通过 xsl:param 指令接受参数,像下面这样:
<xsl:template name="print">
<xsl:param name="message"/>
<!-- template content goes here -->
</xsl:template>
xsl:call-template 指令用于调用命名模板(而不是 xsl:apply-templates),比如:
<xsl:call-template name="print">
<xsl:with-param name="message"
select="'See if it prints this message.'"/>
</xsl:call-template>
清单 3 是对 清单 2 的改写,它使得树的遍历算法更明显。为了避免依靠处理程序操作树
,这个样式表有一个命名模板 main 实现了树的遍历。main 是一个递归函数,它用 curren
t 参数接受一个节点集并遍历该节点集。模板的主要部分是一条 choose 指令,为给定的节
点寻找最适当的规则。在处理一个节点时,该模板递归地调用自身,以便处理该节点的孩子
。
清单 3. 公开遍历算法的样式表
<?xml version="1.0"?>
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:db="http://ananas.org/2002/docbook/subset">
<xsl:output method="html"/>
<xsl:template match="/">
<xsl:call-template name="main">
<xsl:with-param name="nodes" select="."/>
</xsl:call-template>
</xsl:template>
<xsl:template name="main">
<xsl:param name="nodes"/>
<xsl:for-each select="$nodes">
<xsl:choose>
<xsl:when test="self::db:article">
<html>
<head><title>
<xsl:value-of select="db:title"/>
</title></head>
<body>
<xsl:call-template name="main">
<xsl:with-param name="nodes" select="child::node()"/>
</xsl:call-template>
</body>
</html>
</xsl:when>
<xsl:when test="self::db:para">
<p>
<xsl:call-template name="main">
<xsl:with-param name="nodes" select="child::node()"/>
</xsl:call-template>
</p>
</xsl:when>
<xsl:when test="self::db:ulink">
<a href="{@url}">
<xsl:call-template name="main">
<xsl:with-param name="nodes" select="child::node()"/>
</xsl:call-template>
</a>
</xsl:when>
<xsl:when test="self::db:title[parent::db:article]">
<h1>
<xsl:call-template name="main">
<xsl:with-param name="nodes" select="child::node()"/>
</xsl:call-template>
</h1>
</xsl:when>
<xsl:when test="self::db:title">
<h2>
<xsl:call-template name="main">
<xsl:with-param name="nodes" select="child::node()"/>
</xsl:call-template>
</h2>
</xsl:when>
<xsl:when test="self::db:emphasis[@role='bold']">
<b>
<xsl:call-template name="main">
<xsl:with-param name="nodes" select="child::node()"/>
</xsl:call-template>
</b>
</xsl:when>
<xsl:when test="self::db:emphasis">
<i>
<xsl:call-template name="main">
<xsl:with-param name="nodes" select="child::node()"/>
</xsl:call-template>
</i>
</xsl:when>
<xsl:when test="self::text()">
<xsl:value-of select="."/>
</xsl:when>
<xsl:otherwise>
<xsl:call-template name="main">
<xsl:with-param name="nodes" select="child::node()"/>
</xsl:call-template>
</xsl:otherwise>
</xsl:choose>
</xsl:for-each>
</xsl:template>
</xsl:stylesheet>
如果比较清单 2 和清单 3,就会发现它们在结构上是一致的。在 清单 2 中,巨大的 choo
se 指令是通过模板在幕后实现的。不需要显式地写上 choose 指令,但这确实是处理程序
工作的方式。比较清单 2 中的模板和 清单 3 中的测试条件,就会发现存在一一对应的关
系。
即使清单 3 中的最后两个测试,也通过默认模板与清单 2 对应。虽然得益于默认模板,清
单 2 中不需要明确地写出这两个模板,处理程序确实有两个模板,一个用于文本内容和另
一个“catch-all”模板。
清单 2 中,xsl:apply-templates 指令代替了递归调用。在很多方面,可以认为 xsl:appl
y-templates 是对样式表自身的递归调用!它告诉处理程序移到当前节点的孩子,并尝试寻
找另一个适用的模板。清单 3 中的循环和测试非常明显,而在清单 2 中是由处理程序隐含
完成的。在清单 3 中, 模板使用了一个额外的参数表示当前节点,而在清单 2 中,该参
数是隐式的。xsl:apply-templates 自动改变当前节点。
最后但同样重要的一点是模板参数。在 清单 3,模板使用参数表示要处理的节点。在 清单
2,模板不需要参数,因为处理程序负责管理当前节点。当前节点总是指向模板所应用的节
点。当前节点就像是一个隐式参数。
结束语
事实上,没有人会编写 清单 3 这样的样式表。这个例子仅用于教学,但确实可以说明处理
程序在幕后是如何工作的。通过比较清单 2 和清单 3,可以看出处理程序处理了很多基本
代码(比如循环和传递参数),以便实现深度优先的搜索。编写下一个样式表时要把这些记
在脑子里,也许您会发现它改变了您编码的方式。
比如,不再像 XSLT 新手常做的那样编写这种代码:
<xsl:template match="db:emphasis">
<xsl:choose>
<xsl:when test="@role='bold'">
<b><xsl:apply-templates/></b>
</xsl:when>
<xsl:otherwise><i><xsl:apply-templates/></i></xsl:otherwise>
</xsl:choose>
</xsl:template>
您可以改写成下面这样,如果考虑到处理程序的工作原理,它们是完全等价的:
<xsl:template match="db:emphasis[@role='bold']">
<b><xsl:apply-templates/></b>
</xsl:template>
<xsl:template match="db:emphasis">
<i><xsl:apply-templates/></i>
</xsl:template>
我希望已经说明了 XSLT 处理程序的内部工作原理。很好地理解这一点对于改进您的样式表
编码非常重要。
 此主题相关图片如下:
此主题相关图片如下: